Introduction
What is sensitive data?
Sensitive data are data that can be used to identify an individual, species, object, or location that introduces a risk of discrimination, harm, or unwanted attention.
- Australian Research Data Commons
If your data involves human participants it may be sensitive data, even if no personal identifiers are collected. For instance, through the course of participating in an anonymous survey, participants may inadvertently share highly private details which enable their identities to be inferred
If in any doubt as to the sensitivity of your data, consult the Office of Human Ethics, Biosafety, and Integrity.
Other forms of sensitive data can include:
- Confidential data e.g.:
- Patient/participant personally identifiable information
- Commercial in-confidence information and research
- Ecological data that may place vulnerable species at risk
- Data not wholly owned by the researchers e.g.:
- Data owned or co-owned by participants or a representative committee
- Data owned or co-owned by a commercial company or other enterprise
- Data involving Indigenous people - La Trobe University’s Research Data Management Policy states you must “consult with research participants and communities regarding the methods of collecting, storing and accessing the data.”
Even data that is not obviously sensitive (i.e., does not include names or dates of birth), or has been de-identified, may become sensitive again when context changes.
- Triangulation (combining several pieces of non-sensitive information e.g. age, family composition, occupation).
- Data linkage- bringing two or more datasets together that cover same person or subject of research.
What data can I share?
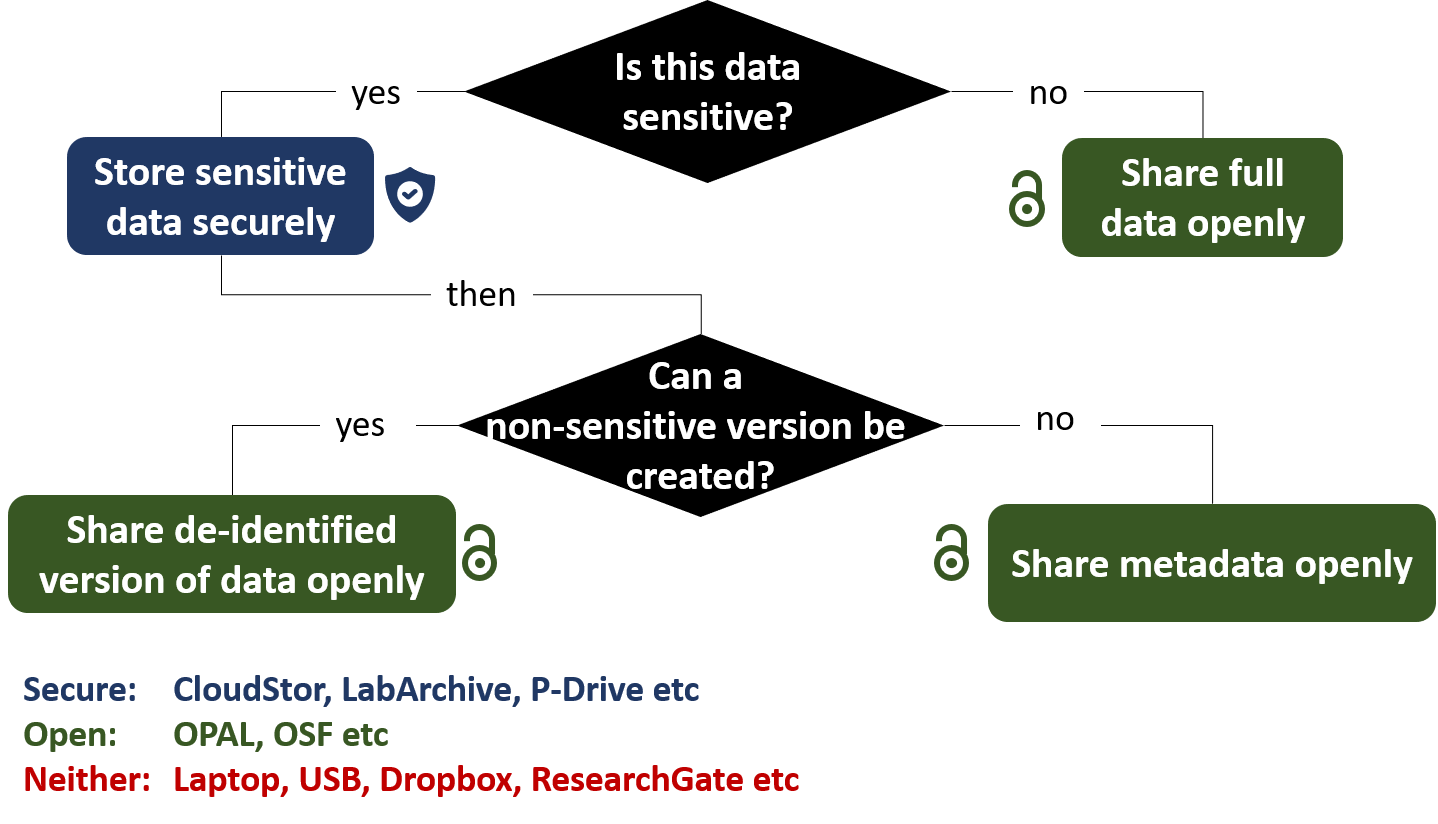
Open sharing in the university’s open repository (OPAL) is mandatory for metadata. Additionally, sharing the raw data is mandatory unless it cannot be safely released due to data sensitivity, specific commercial potential or third party contractual agreement. In such cases a de-identified dataset (e.g. with some data anonymised, aggregated, omitted) may be released, or in extreme cases, metadata only.
You can think about it via these options:
|
Open access (recommended via OPAL) Mandatory unless sensitivity reason given |
Mediated access (upon request) Researcher or committee discretion |
No access (confidential) Never to be released |
|
|
Full dataset(s) All data required to replicate analyses (may include data not used in published analyses) |
This is the default for a non sensitive dataset (See guide on data sharing) |
This is commonly used if the raw data is too sensitive to be public, but safe enough for other researchers to request. Don't forget to indicate who will make the decision whether to share. |
This is the fallback if you don't select either option on the left. |
|
Modified / redacted / de-identified dataset(s) Data altered to be non-sensitive. Must indicate how was modified from full dataset (e.g. which elements anonymised, aggregated, omitted etc.) |
This is the option if the dataset is sensitive, but you can safely remove identifying information. Don't forget to specify what changes were made during de-identification. (See guides on de-identification and redaction) |
This option may be needed if the raw data is so sensitive that it shouldn't be shared with other researchers even upon request. Don't forget to indicate who will make the decision whether to share. |
This is the fallback if you don't select either option on the left. |
|
Dataset metadata Description of dataset only, not actual data (e.g. description of dataset size, content, date of creation) |
This is the fallback if you don't select either option above. Don't forget to also include one of the options in the right-hand columns for whether researchers can request the data itself. (See guide on metadata) |
This is rarely necessary if the metadata itself is sensitive | This is pretty much never relevant. This generally means that only the gathering researcher can ever know this data. |
Useful Links
- ARDC - working with sensitive dataResources covering many aspects and considerations about working with sensitive data
- IQDA Qualitative Data AnonymizerThe Irish Qualitative Data Archive's data anonymization tool is ideal for researchers who wish to publish their work to digital archives