Statistical techniques
Some commonly used statistical techniques
Correlation analysis
Correlation analysis explores the association between variables. The purpose of correlational analysis is to discover whether there is a relationship between variables, which is unlikely to occur by sampling error. The null hypothesis is that there is no relationship between the two variables. Correlation analysis provides information about:
- The direction of the relationship: positive or negative- given by the sign of the correlation coefficient.
- The strength or magnitude of the relationship between the two variables- given by the correlation coefficient, which varies from 0 (no relationship between the variables) to 1 (perfect relationship between the variables).
- Direction of the relationship.
A positive correlation indicates that high scores on one variable are associated with high scores on the other variable; low scores on one variable are associated with low scores on the second variable . For instance, in the figure below, higher scores on negative affect are associated with higher scores on perceived stress

A negative correlation indicates that high scores on one variable are associated with low scores on the other variable. The graph shows that a person who scores high on perceived stress will probably score low on mastery. The slope of the graph is downwards- as it moves to the right. In the figure below, higher scores on mastery are associated with lower scores on perceived stress.
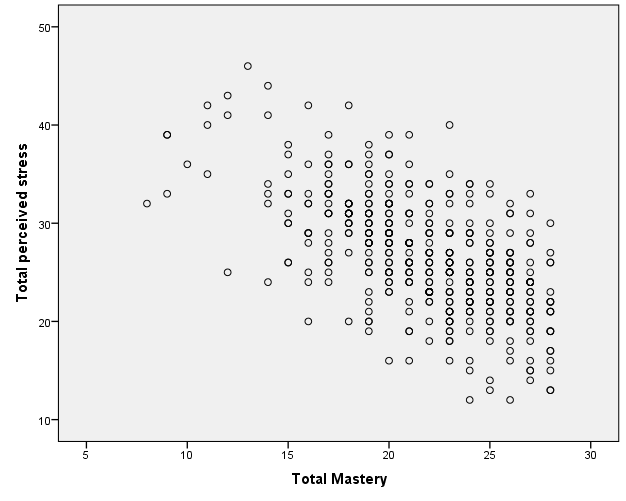
Fig 2. Negative correlation between two variables. Adapted from Pallant, J. (2013). SPSS survival manual: A step by step guide to data analysis using IBM SPSS (5th ed.). Sydney, Melbourne, Auckland, London: Allen & Unwin
2. The strength or magnitude of the relationship
The strength of a linear relationship between two variables is measured by a statistic known as the correlation coefficient, which varies from 0 to -1, and from 0 to +1. There are several correlation coefficients; the most widely used are Pearson’s r and Spearman’s rho. The strength of the relationship is interpreted as follows:
- Small/weak: r= .10 to .29
- Medium/moderate: r= .30 to .49
- Large/strong: r= .50 to 1
It is important to note that correlation analysis does not imply causality. Correlation is used to explore the association between variables, however, it does not indicate that one variable causes the other. The correlation between two variables could be due to the fact that a third variable is affecting the two variables.
Multiple regression
Multiple regression is an extension of correlation analysis. Multiple regression is used to explore the relationship between one dependent variable and a number of independent variables or predictors. The purpose of a multiple regression model is to predict values of a dependent variable based on the values of the independent variables or predictors. For example, a researcher may be interested in predicting students’ academic success (e.g. grades) based on a number of predictors, for example, hours spent studying, satisfaction with studies, relationships with peers and lecturers.
A multiple regression model can be conducted using statistical software (e.g. SPSS). The software will test the significance of the model (i.e. does the model significantly predicts scores on the dependent variable using the independent variables introduced in the model?), how much of the variance in the dependent variable is explained by the model, and the individual contribution of each independent variable.
Example of multiple regression model
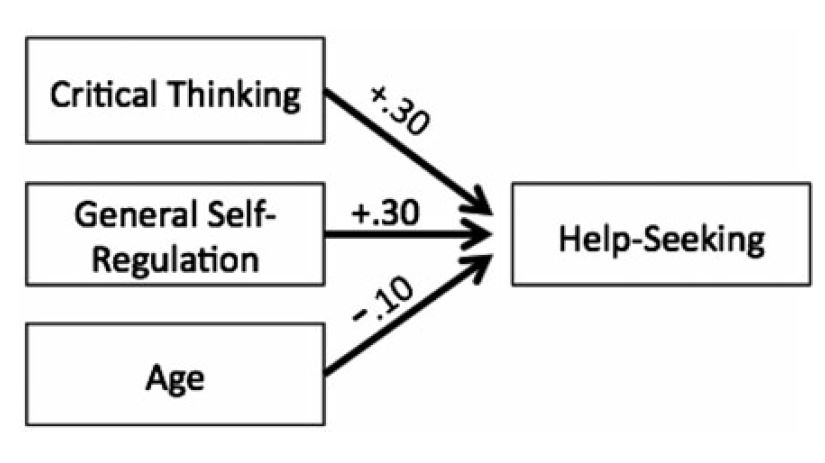
From Dunn et al. (2014). Influence of academic self-regulation, critical thinking, and age on online graduate students' academic help-seeking.
In this model, help-seeking is the dependent variable; there are three independent variables or predictors. The coefficients show the direction (positive or negative) and magnitude of the relationship between each predictor and the dependent variable. The model was statistically significant and predicted 13.5% of the variance in help-seeking.
t-Tests
t-Tests are employed to compare the mean score on some continuous variable for two groups. The null hypothesis to be tested is there are no differences between the two groups (e.g. anxiety scores for males and females are not different).
If the significance value of the t-test is equal or less than .05, there is a significant difference in the mean scores on the variable of interest for each of the two groups. If the value is above .05, there is no significant difference between the groups.
t-Tests can be employed to compare the mean scores of two different groups (independent-samples t-test) or to compare the same group of people on two different occasions (paired-samples t-test).
In addition to assessing whether the difference between the two groups is statistically significant, it is important to consider the effect size or magnitude of the difference between the groups. The effect size is given by partial eta squared (proportion of variance of the dependent variable that is explained by the independent variable) and Cohen’s d (difference between groups in terms of standard deviation units).
In this example, an independent samples t-test was conducted to assess whether males and females differ in their perceived anxiety levels. The significance of the test is .004. Since this value is less than .05, we can conclude that there is a statistically significant difference between males and females in their perceived anxiety levels.

ANOVA
Whilst t-tests compare the mean score on one variable for two groups, analysis of variance is used to test more than two groups. Following the previous example, analysis of variance would be employed to test whether there are differences in anxiety scores for students from different disciplines.
Analysis of variance compare the variance (variability in scores) between the different groups (believed to be due to the independent variable) with the variability within each group (believed to be due to chance). An F ratio is calculated; a large F ratio indicates that there is more variability between the groups (caused by the independent variable) than there is within each group (error term). A significant F test indicates that we can reject the null hypothesis; i.e. that there is no difference between the groups.
Again, effect size statistics such as Cohen’s d and eta squared are employed to assess the magnitude of the differences between groups.
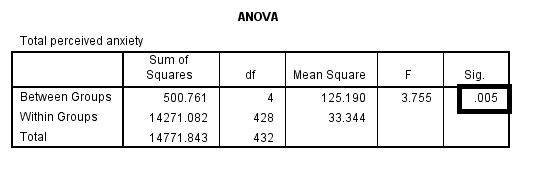
In this example, we examined differences in perceived anxiety between students from different disciplines. The results of the Anova Test show that the significance level is .005. Since this value is below .05, we can conclude that there are statistically significant differences between students from different disciplines in their perceived anxiety levels.
Chi-square test for independence
Chi-square test for independence is used to explore the relationship between two categorical variables. Each variable can have two or more categories.
For example, a researcher can use a Chi-square test for independence to assess the relationship between study disciplines (e.g. Psychology, Business, Education,…) and help-seeking behaviour (Yes/No). The test compares the observed frequencies of cases with the values that would be expected if there was no association between the two variables of interest. A statistically significant Chi-square test indicates that the two variables are associated (e.g. Psychology students are more likely to seek help than Business students). The effect size is assessed using effect size statistics: Phi and Cramer’s V.
In this example, a Chi-square test was conducted to assess whether males and females differ in their help-seeking behaviour (Yes/No). The crosstabulation table shows the percentage of males of females who sought/didn't seek help. The table 'Chi square tests' shows the significance of the test (Pearson Chi square asymp sig: .482). Since this value is above .05, we conclude that there is no statistically significant difference between males and females in their help-seeking behaviour.
